Add and overwrite data#
Generally, datasets in primap2 follow the xarray convention that the data within
datasets is immutable.
To change any data, you need to create a view or a copy of the dataset with the changes
applied.
To this end, we provide a set function to set specified data.
It can be used to only fill gaps, add wholly new data, or overwrite existing data in
the dataset.
The set functions#
We provide xarray.DataArray.pr.set() and xarray.Dataset.pr.set() functions,
for DataArrays (individual gases) and Datasets (multiple gases), respectively.
The basic signature of the set functions is set(dimension, keys, values), and it
returns the changed object without changing the original one.
Use it like this:
# setup: import library and open dataset
import primap2
ds_min = primap2.open_dataset("../minimal_ds.nc")
# Now, select CO2 a slice of the CO2 data as an example to use
da = ds_min["CO2"].loc[{"time": slice("2000", "2005")}]
da
<xarray.DataArray 'CO2' (time: 6, area (ISO3): 4, source: 1)> Size: 192B
<Quantity([[[0.66352018]
[0.91683183]
[0.10638745]
[0.61416341]]
[[0.33822533]
[0.68233863]
[0.73953851]
[0.79057726]]
[[0.11409101]
[0.25072807]
[0.85044897]
[0.40873907]]
[[0.80147707]
[0.85209597]
[0.71521289]
[0.08031265]]
[[0.61018888]
[0.88112521]
[0.55500009]
[0.11105145]]
[[0.81245612]
[0.14774848]
[0.14072429]
[0.13586946]]], 'CO2 * gigagram / year')>
Coordinates:
* area (ISO3) (area (ISO3)) <U3 48B 'COL' 'ARG' 'MEX' 'BOL'
* source (source) <U8 32B 'RAND2020'
* time (time) datetime64[ns] 48B 2000-01-01 2001-01-01 ... 2005-01-01
Attributes:
entity: CO2import numpy as np
from primap2 import ureg
# generate new data for Cuba
new_data_cuba = np.linspace(0, 20, 6) * ureg("Gg CO2 / year")
# Actually modify our original data
modified = da.pr.set("area", "CUB", new_data_cuba)
modified
<xarray.DataArray 'CO2' (time: 6, area (ISO3): 5, source: 1)> Size: 240B
<Quantity([[[ 0.91683183]
[ 0.61416341]
[ 0.66352018]
[ 0. ]
[ 0.10638745]]
[[ 0.68233863]
[ 0.79057726]
[ 0.33822533]
[ 4. ]
[ 0.73953851]]
[[ 0.25072807]
[ 0.40873907]
[ 0.11409101]
[ 8. ]
[ 0.85044897]]
[[ 0.85209597]
[ 0.08031265]
[ 0.80147707]
[12. ]
[ 0.71521289]]
[[ 0.88112521]
[ 0.11105145]
[ 0.61018888]
[16. ]
[ 0.55500009]]
[[ 0.14774848]
[ 0.13586946]
[ 0.81245612]
[20. ]
[ 0.14072429]]], 'CO2 * gigagram / year')>
Coordinates:
* area (ISO3) (area (ISO3)) <U3 60B 'ARG' 'BOL' 'COL' 'CUB' 'MEX'
* source (source) <U8 32B 'RAND2020'
* time (time) datetime64[ns] 48B 2000-01-01 2001-01-01 ... 2005-01-01
Attributes:
entity: CO2By default, existing non-NaN values are not overwritten:
try:
da.pr.set("area", "COL", np.linspace(0, 20, 6) * ureg("Gg CO2 / year"))
except ValueError as err:
print(err)
Values {'COL'} for 'area (ISO3)' already exist and contain data. Use existing='overwrite' or 'fillna' to avoid this error.
You can overwrite existing values by specifying existing="overwrite"
to overwrite all values or existing="fillna" to overwrite only NaNs.
da.pr.set(
"area",
"COL",
np.linspace(0, 20, 6) * ureg("Gg CO2 / year"),
existing="overwrite",
)
<xarray.DataArray 'CO2' (time: 6, area (ISO3): 4, source: 1)> Size: 192B
<Quantity([[[ 0.91683183]
[ 0.61416341]
[ 0. ]
[ 0.10638745]]
[[ 0.68233863]
[ 0.79057726]
[ 4. ]
[ 0.73953851]]
[[ 0.25072807]
[ 0.40873907]
[ 8. ]
[ 0.85044897]]
[[ 0.85209597]
[ 0.08031265]
[12. ]
[ 0.71521289]]
[[ 0.88112521]
[ 0.11105145]
[16. ]
[ 0.55500009]]
[[ 0.14774848]
[ 0.13586946]
[20. ]
[ 0.14072429]]], 'CO2 * gigagram / year')>
Coordinates:
* area (ISO3) (area (ISO3)) <U3 48B 'ARG' 'BOL' 'COL' 'MEX'
* source (source) <U8 32B 'RAND2020'
* time (time) datetime64[ns] 48B 2000-01-01 2001-01-01 ... 2005-01-01
Attributes:
entity: CO2By default, the set() function extends the specified dimension automatically to
accommodate new values if not all key values are in the specified dimension yet.
You can change this by specifying new="error", which will raise a KeyError if any of
the keys is not found:
try:
da.pr.set(
"area",
["COL", "CUB"],
np.linspace(0, 20, 6) * ureg("Gg CO2 / year"),
existing="overwrite",
new="error",
)
except KeyError as err:
print(err)
"Values {'CUB'} not in 'area (ISO3)', use new='extend' to automatically insert new values into dim."
Example: computing super-categories#
In particular, the set() functions can also be used with xarray’s arithmetic
functions to derive values from existing data and store the result in the Dataset.
As an example, we will derive better values for category 0 by adding all
its subcategories and store the result.
First, let’s load a dataset and see the current data for a small subset of the data:
ds = primap2.open_dataset("../opulent_ds.nc")
sel = {
"area": "COL",
"category": ["0", "1", "2", "3", "4", "5"],
"animal": "cow",
"product": "milk",
"scenario": "highpop",
"source": "RAND2020",
}
subset = ds.pr.loc[sel].squeeze()
# TODO: currently, plotting with units still emits a warning
import warnings
with warnings.catch_warnings():
warnings.simplefilter("ignore")
subset["CO2"].plot.line(x="time", hue="category (IPCC 2006)")
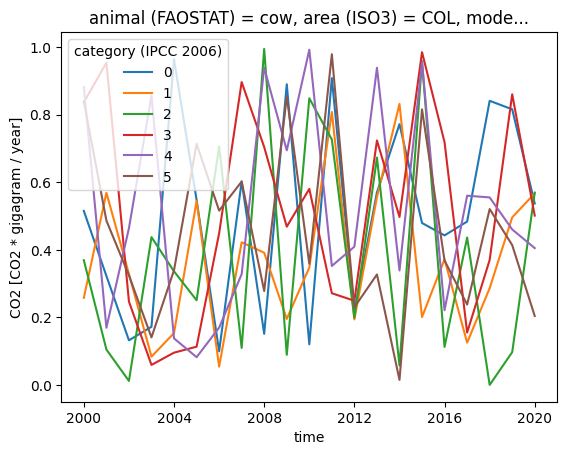
While it is hard to see any details in this plot, it is clearly visible that category 0 is not the sum of the other categories (which should not come as a surprise because the data were generated at random).
We will now recompute category 0 for the entire dataset using set():
cat0_new = ds.pr.loc[{"category": ["1", "2", "3", "4", "5"]}].pr.sum("category")
ds = ds.pr.set(
"category",
"0",
cat0_new,
existing="overwrite",
)
# plot a small subset of the result
subset = ds.pr.loc[sel].squeeze()
# TODO: currently, plotting with units still emits a warning
import warnings
with warnings.catch_warnings():
warnings.simplefilter("ignore")
subset["CO2"].plot.line(x="time", hue="category (IPCC 2006)")
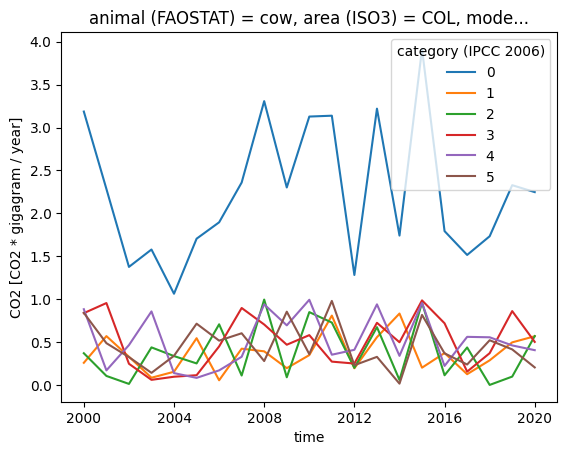
As you can see in the plot, category 0 is now computed from its subcategories. The set() method of Datasets works on all data variables in the dataset which have the corresponding dimension. In this example, the “population” variable does not have categories, so it was unchanged.